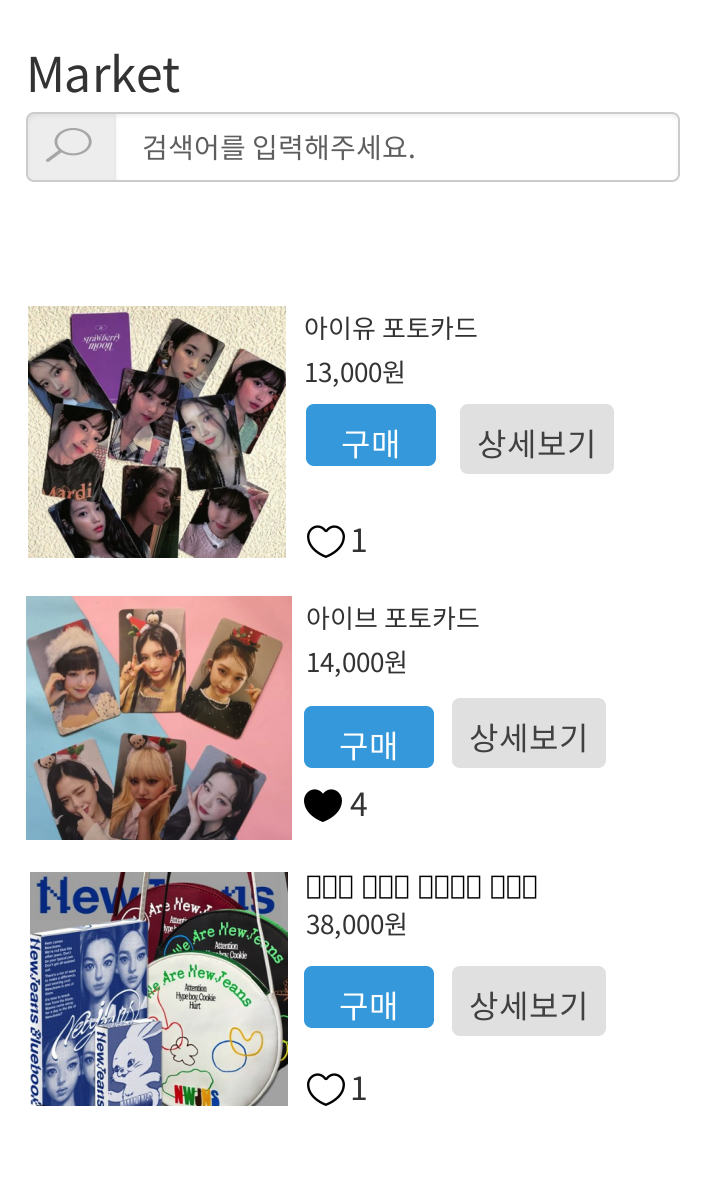
현재 굿즈포유 프로젝트에서는, 다음과 같이 등록된 상품의 목록을 조회할 수 있는 기능이 있습니다. 굿즈포유 서비스의 메인이 되는 화면이기에 메인 기능이라고 볼 수 있습니다. (페이징 처리 관련한 코드를 확인하고 싶으신 분들은 링크를 참고해주세요)
이러한 상품 목록을 조회기능을 구현할 때, 단순히 아래와 같은 쿼리를 이용해 구현할 수도 있습니다.
SELECT * FROM PRODUCT;
만약, 해당 서비스에 등록된 상품의 수가 적은 경우에는 별다른 문제점이 없을 것 입니다.
하지만 적재된 데이터가 10만 건, 100만건.. 많은 양의 데이터가 존재한다면 테이블 전체를 스캔하는 쿼리의 작업 시간은 매우 오래 걸릴 것 입니다.

위 그림은 실제로 약 102만건의 데이터를 조회하는데 걸린 시간입니다.
실행 시간은 15.8초 정도 입니다. 만약 사용자가 서비스를 이용하면서, 상품 목록을 조회할때 15초가 걸린다면 해당 서비스를 이용하는데 있어 많은 불편을 겪게 될 것입니다. 또한 102만건의 데이터를 한번에 가져와야 할 필요도 없어 보이기에, 페이징 처리 방식을 도입하기로 했습니다.

간단하게 LIMIT , offset 키워드를 통해, 상품 데이터를 10개씩 가져오도록 한 결과 입니다. 이렇게 함으로써, 데이터 조회에 걸리는 시간을 15.8초 → 0.09초로 대폭 줄일 수 있었습니다.
하지만 만약 offset을 통해, 가져올 10건의 데이터의 위치가 테이블의 마지막에 위치하게 된다면 어떻게 될까요?

마지막 페이지에 존재하는 데이터 조회에 걸리는 시간은 0.2초 정도로 첫페이지 조회 시간인 0.09초에 비해 많이 느려졌음을 알 수 있습니다.
그렇다면 왜 LIMIT과, offset을 기반으로한 목록 조회 처리 속도가 느려지는지 간단히 알아보겠습니다.
앞서 설명드린 offset 기반의 페이징 쿼리는 다음과 같습니다.
select * from PRODUCT LIMIT 페이지 사이즈 offset 페이지번호;
이와 같은 페이징 쿼리는 앞페이지 조회 때 읽었던 행을 뒷 페이지 조회시 다시 읽어야 하기 때문에 성능 저하가 생기게 됩니다.

위 그림 처럼 limit 10, offset 1000000 이라 하면 최종적으로는 1000010 개의 행을 읽어야 합니다, 그리고 그 중 불필요한 10_000_00개의 행을 버리게 됩니다.
어떻게 조회 쿼리의 성능을 개선할 수 있을까요? 결론부터 말씀드리면 No Offset 방식을 채택 함으로써, 해결 했습니다.

No Offset 방식으로 마지막 페이지의 데이터를 조회한 결과 입니다.
실행 시간은 0.2초 → 0.03초로 성능이 향상되었음을 알 수 있습니다.
그렇다면 No Offset 방식은 왜 Offset 방식보다 조회 속도가 빠른걸까요?
조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만 읽도록 하는 방식이기에 빠르게 조회할 수 있습니다.
또한 클러스터 인덱스인 PK를 조회 시작 부분 조건문으로 사용했기에 빠르게 조회 할 수있습니다.
클러스터 인덱스
-
더보기클러스터 인덱스는 테이블 전체가 정렬된 인덱스가 되는 방식의 인덱스 종류 입니다. 실제 데이터와 클러스터링을 해 인덱싱 되므로 클러스터 인덱스라고 부릅니다. 이 인덱스는 데이터와 함께 전체 테이블이 물리적으로 정렬됩니다. 예를 들어 클러스터 인덱스는 영어 사전과 비슷하다고 볼 수 있습니다. 영어 사전은 영어 알파벳 순으로 정렬되어 있으면서, 각 영어 단어의 뜻도 존재하기 때문입니다. 또한 특정 컬럼을 PK로 지정하면 클러스터 인덱스를 생성합니다. 따라서 위 이미지에서도 id 값을 PK로 설정했기에 id값이 클러스터 인덱스가 된 것 입니다.
두 조회 방식의 실행계획 비교

offset 기반의 조회 쿼리 실행시의 실행 계획입니다.
type이 ALL이기에 테이블 풀 스캔이 일어 났고, 그에 따라 1015270개의 row를 조회했습니다.

NoOffset 기반의 조회 쿼리 실행시의 실행 계획입니다.
type은 index range 스캔이 일어났고, 조회된 rows의 수는 506735로 앞서 조회한 쿼리의 절반 밖에 데이터 조회가 일어나지 않았습니다.
NoOffset 기반 쿼리의 단점
- where에 사용되는 기준 Key가 중복이 가능할 경우
- 만약 집계 함수인 group by 등을 사용할 때 기준으로 잡을 key가 noOffset의 기준 Key와 중복이 될 경우 정확한 결과를 반환할 수 없기에 해당 방식을 사용할 수 없습니다
- 서비스 정책상 더보기(또는 More)버튼은 안되며, 무조건 각각의 페이지 버튼을 통해서 페이징 처리를 해야 한다하면 해당 방식을 사용할 수가 없습니다..
- NoOffset은 순차적으로 다음페이지로 이동만 가능하기 때문에, 1~9 페이지 사이의 페이지 버튼을 눌러서 해당 페이지로 바로 가는 식의 페이징 기능으로 사용할 수 없습니다.
NoOffset 이외의 성능 개선을 위한 대안
만약 앞서 설명한 이유들로 No Offset 방식을 사용할 수 없다면, 커버링 인덱스를 통해 성능을 개선할 수 있습니다.
이와 관련해 jojoldu님이 자세히 잘 정리해주신 글이 있으니 관심있으신 분들은 해당 글을 참고해주세요.
참고자료
'프로그래밍 > 프로젝트' 카테고리의 다른 글
| JMeter를 통한 부하테스트 (1) | 2023.06.03 |
|---|---|
| 테스트 시, Redis Session 으로 인해 생긴 문제 해결 (0) | 2023.04.19 |
| SQL Injection (0) | 2023.04.05 |
| Builder 패턴? (0) | 2023.04.05 |
| 테스트 커버리지를 70% 이상 유지하면서 느낀점 (0) | 2023.03.21 |