Spring Data Common 개요
Spring Data Common 에서 Repository를 추상화해서 통해 얻고자 하는 목표는 다양한 영속성 저장소(RDBMS, NoSQL 등등..)에 대한 데이터 접근 계층을 구현할 때 필요한 상용구 코드의 양을 크게 줄이는 것 입니다.(Connection과 관련된 코드 등등..)

Repository
Spring Data Common 에서 Repository 추상화의 핵심 인터페이스는 Repository 입니다. 이 인터페이스는 관리할 도메인 클래스와 도메인 클래스의 ID 유형을 type arguments(Repository<T,ID> 와 같은 형식)로 받습니다.
Repository 인터페이스는 주로 작업할 유형을 캡쳐하고, 이 인터페이스를 확장하는 인터페이스를 찾을 수 있도록 도와주는 마커 인터페이스(Marker Interface)역할을 합니다.
CrudRepository
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
Optional<T> findById(ID primaryKey);
Iterable<T> findAll();
long count();
void delete(T entity);
boolean existsById(ID primaryKey);
// … more functionality omitted.
}
CrudRepository 및 ListCrudRepository 인터페이스는 관리 중인 엔티티 클래스에 대한 정교한 CRUD 기능을 제공합니다.
public interface ListCrudRepository<T, ID> extends CrudRepository<T, ID> {
<S extends T> List<S> saveAll(Iterable<S>entities);
List<T> findAll();
List<T> findAllById(Iterable<ID>ids);
}
ListCrudRepository 는 CrudRepository 와 동등한 메서드를 제공하지만, findAll() 메서드의 경우 CrudRepository는 Iterable<T> 를 반환하지만, ListCrudRepository는 List<T> 를 반환합니다.
PagingAndSortingRepository
PagingAndSortingRepository 는 추상화를 통해, 엔티티에 대한 페이지와 정렬 관련된 접근을 용이하게 하는 인터페이스 입니다.
public interface PagingAndSortingRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
Repository Pattern

Repository Pattern은 데이터 접근과 조작에 집중한 영속성 계층(구현 기술)과 도메인 계층을 분리시키는 것을 의미합니다.
이 과정에서 Repository라는 추상화를 둠으로써 도메인 계층에서 영속성 계층에 직접적으로 의존을 하는 것이 아닌, Repository라는 추상화된 객체를 의존해, 도메인 계층과 영속성 계층의 직접적인 의존을 역전(Dependency Inversion Principle)시킬 수 있습니다.
Domain의 관점에서는 Repository라는 추상화된 객체에서 데이터를 조작하는데 필요한 인터페이스를 제공해주고, 그 인터페이스를 토대로, 원하는 결과만 받아올 수 있기 때문에, 영속성 계층에서 실제 데이터가 어떻게 조작되는지는 알 필요가 없게 됩니다.
그렇다면 Spring Data Jpa 에서 제공하는 JpaRepository의 상속관계는 어떻게될까요?
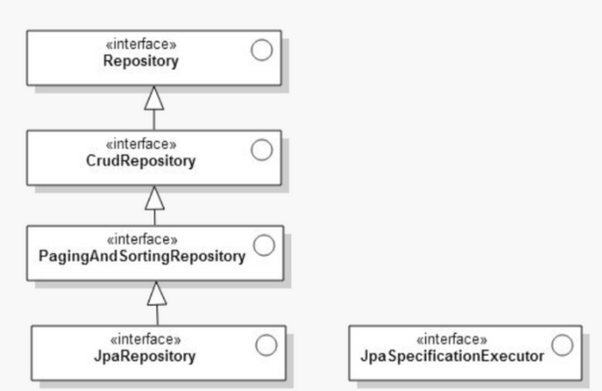
위 그림의 Repository가 가장 고 수준 모듈이며, JpaRepository는 저 수준 모듈 입니다.(기능 구현이 가장 많이 되어 있습니다) 가장 저 수준 모듈에 속해 있는, JpaRepository 는 추후 Jpa를 사용하는 것이 아닌 MonggoDB를 사용한다 던지 등의, 데이터베이스 사용의 변화가 있을 시에, 가장 하위 수준의 모듈만 변경되면 되기 때문에, 외부 환경의 변화에도 상위 Repository와, CrudRepository, PagingAndSortingRepository는 모든 데이터 접근 및 조작 모듈에서 공통으로 사용하는 부분이기에 변화가 이루어지지 않아도 된다는 장점이 있습니다.

그림과 같이 Spring Common Module에 속한 Repository, CrudRepository, PagingAndSortingRepository를 통해 그 하위 저장소로 Jpa,Mongo,Graph등등 어떤것을 사용하게 되더라도, 저 수준 모듈의 변화에 고 수준 모듈이 영향받지 않는 다는 점을 알 수 있습니다.
이처럼 Spring data common 모듈과 그 하위 Jpa,Mongo 모듈을 살펴보면서 스프링에서 어떻게 DIP를 적용하고 있을지에 대해 관련한 코드나, 상속 관계등을 살펴 보았습니다.
스프링에서는 DIP를 통해, 스프링을 사용하는 개발자가 하위 수준의 Jpa또는 Mongo, Graph등 데이터 저장 기술의 변화에 애플리케이션의 핵심 로직인 도메인 영역이 영향받지 않도록 구현할 수 있도록 구현을 해놓은 것이 아닐까 라고 생각했습니다.
참고
https://wonit.tistory.com/m/636
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/
Spring Data JPA - Reference Documentation
Example 121. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
'프로그래밍 > Spring' 카테고리의 다른 글
| mock() vs @Mock vs @MockBean 이제 그만 헷갈리자! (0) | 2023.06.25 |
|---|---|
| Micro Service에서 WebFlux의 장점 (0) | 2022.12.28 |
| Spring WebMVC VS WebFlux (0) | 2022.12.28 |